基本概念
首先弄清楚子域名与子目录的区别。
子目录是网站下面的目录,而子域名是上一级域名下面的域名。
不同的域名可以是不同的网站,例如:www.abc.qq.com和www.123.qq.com。这里abc和123都是qq下面的子域名。com为顶级域名,qq为一级域名,abc和123是二级域名。
而www.qq.com/abc/ 和 www.qq.com/123/ 这两个是一个网站下的两个目录。
域名解析的过程下: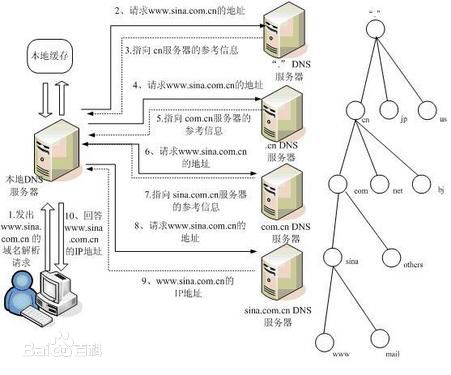
目标
EE(Everything Everywhere)是英国最大的移动通信运营商,现已被英国电信BT(BiggerThinking)收购,其网址为http://ee.co.uk/ ,我们现在要找出所有以ee.co.uk结尾的子域名。这应该属于渗透测试的资料收集阶段。
过程
方案一
首先想到的是采用nslookup命令,如下图所示: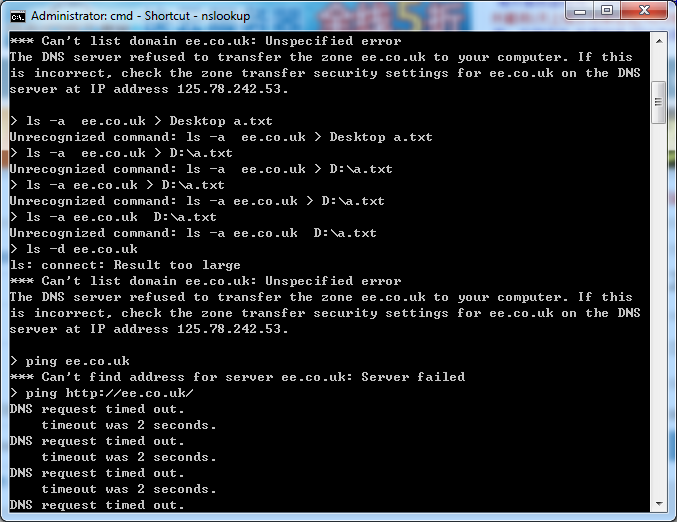
最开始以为是太多显示不了,遂尝试将其写在文件中,后来查资料是由于DNS服务默认当查询结果大于512字节时,就不能返回。这里报错,服务器拒绝呈现,这也是DNS所做的一些保护措施。
方案二
方案一失败后,想到能否通过IP反查?因为我们知道一个域名对应唯一的一个IP地址,但是一个IP地址可能对应多个域名。因此我试图找到网址http://ee.co.uk/ 所对应的IP地址。然后通过该IP,查找其绑定的所有的域名。
首先通过站长之家查到其IP地址,发现有多个IP,全都指向了同一家公司的数据中心。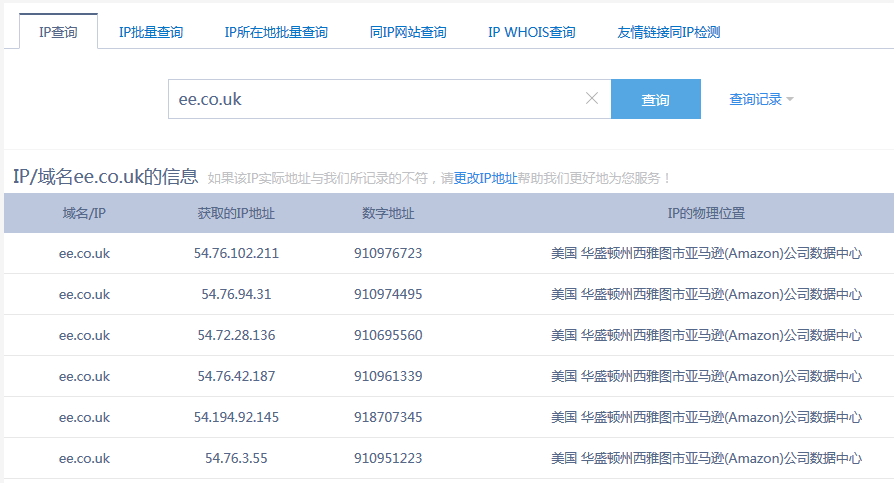
但是当通过IP地址反查时,却发现根本没有任何站点。
可想而知,像这种大型的公司,其域名一定做了加速优化的。因此其IP地址未必是真实的IP地址,遂失败。
方案三
方案二失败后,我想到是否能通过站长之家的Alexa工具,查找得到结果呢?果不其然,得到了如下结果,一共有23个子域名。如下所示: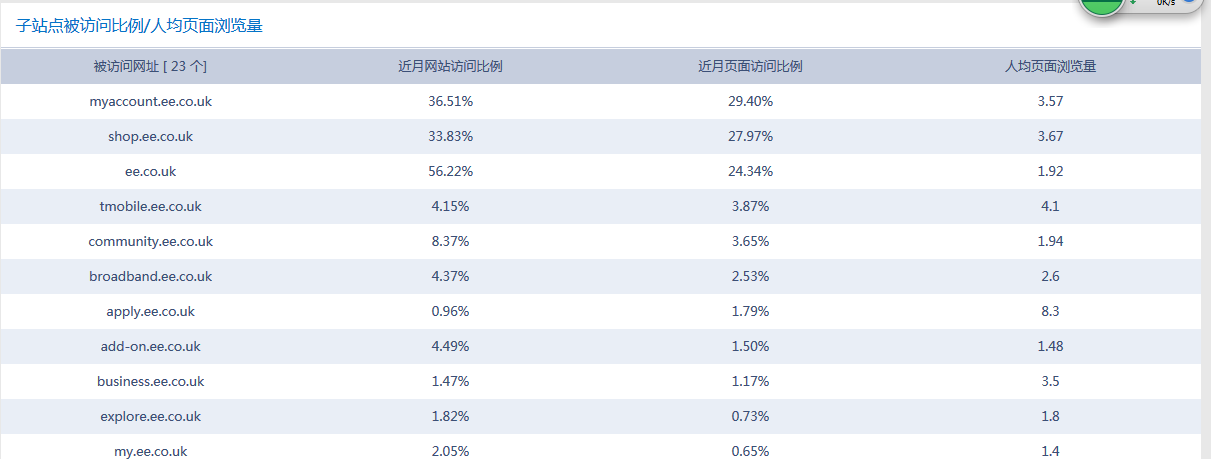
方案四
得到如上结果后,我依然不满足,因为这有可能只是部分结果。因此想到方案四,通过搜索引擎的高级搜索功能进行查找。用谷歌,输入如下命令:1
site:*ee.co.uk
得到如下结果: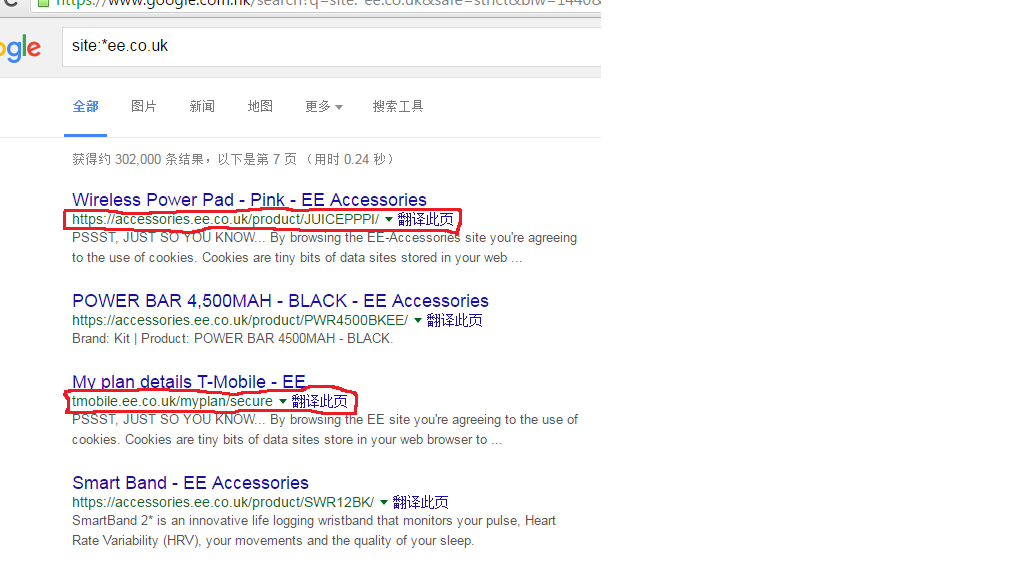
然后用python爬虫的形式,遍历源代码页面,使用正则表达式查找以ee.co.uk结尾的关键字。
参考代码如下:
以下是GetInfoByRegex.py的内容1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63# -*- coding: utf-8 -*-
import re
import urllib
import urllib.request
import os
class GetDataClass:
def __init__(self):
self.url = r'' #待挖掘数据的网页网址
self.regex = r'' #挖掘使用的正则表达式
self.savePath = r'D:' #挖掘出来的结果保存的路径
self.fileName = r'result' #保存结果的文件名字
def SaveResult(self):
status = 'true'
html = getPageHtml(self.url)
List = getWhatUwant(self.regex,html)
outStr=''
for x in range(len(List)):
outStr += List[x]+'\n'
try:
fileWrite = open(self.savePath+"\\"+self.fileName,'w')
fileWrite.writelines(outStr)
except Exception as err:
print (err)
status = 'false'
finally:
fileWrite.close()
return status
#根据输入的网页地址url,获取html源码,将html源码返回
def getPageHtml(url):
html = urllib.request.urlopen(url)
htmlSource = html.read().decode('utf-8')
html.close() #注意一下这里需要关闭
return htmlSource
#根据正则表达式regex在Source中搜索需要的内容,将结果返回
def getWhatUwant(regex,Source):
resultList = re.findall(regex,Source)
return resultList
if __name__ == '__main__':
getData = GetDataClass()
getData.url = 'http://www.baidu.com' #input('请输入url:')
getData.regex = '<body>.*</body>' #input('请输入查找数据的正则表达式:')
getData.savePath = 'd:\\python' #input('请输入保存结果路径:')
getData.fileName = 'info.txt' #input('请输入保存结果文件名:')
status = getData.SaveResult()
if status == 'false':
print ('操作失败')
else:
print ('操作成功')
'''''
getData = GetDataClass()
getData.url = input('')
getData.regex = input('请输入查找数据的正则表达式:')
getData.savePath = input('请输入保存结果路径:')
getData.fileName = input('请输入保存结果文件名:')
'''
以下是主文件main.py的内容:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19# -*- coding: utf-8 -*-
import GetInfoByRegex
import os
try:
getData1 = GetInfoByRegex.GetDataClass()
getData1.url = 'https://www.baidu.com' #input('请输入url:')
getData1.regex = '<title>.* </title>' #input('请输入查找数据的正则表达式:')
getData1.savePath = 'f:' #input('请输入保存结果路径:')
getData1.fileName = 'a.txt' #input('请输入保存结果文件名:')
status = getData1.SaveResult()
if status == 'false':
print ('操作失败')
else:
print ('操作成功')
except Exception as e:
print (e)
以上代码目前还有三个问题没有解决:
- 正则表达式没有写对
- 自动循环遍历页面的代码没有
- 有编码的报错
总结
在理论上是不能把所有子域名都找出来的,只能找出搜索引擎所收录的域名。本文待完善……
【版权声明】
本文首发于戚名钰的博客,欢迎转载,但是必须保留本文的署名戚名钰(包含链接)。如您有任何商业合作或者授权方面的协商,请给我留言:qimingyu.security@foxmail.com
欢迎关注我的微信公众号:科技锐新

本文永久链接:http://qimingyu.github.io/2016/04/12/查找一级域名下面的所有二级域名/

